Quora Insincere Questions Classification

This post provides our solution for Quora Insincere Questions Classification hosted on Kaggle by Quora. This solution ranked 33th on the private leaderboard. The code can be found in this GitHub repository.
Detect Toxic Content to Improve Online Conversations
An existential problem for any major website today is how to handle toxic and divisive content. A key challenge to safe online communication on Quora is to weed out insincere questions – those founded upon false premises, or that intend to make a statement rather than look for helpful answers.
In this competition, the task was to develop a model that can identify and flag insincere questions. The developed solution must provide more scalable methods to detect toxic, misleading content and combat online trolls at scale.
Help Quora uphold their policy of “Be Nice, Be Respectful” and continue to be a place for sharing and growing the world’s knowledge.
Data Overview
In this competition we need to predict whether a question asked on Quora is sincere or not. An insincere question is defined as a question intended to make a statement rather than look for helpful answers. Some characteristics that can signify that a question is insincere:
- Has a non-neutral tone
- Has an exaggerated tone to underscore a point about a group of people
- Is rhetorical and meant to imply a statement about a group of people
- Is disparaging or inflammatory
- Suggests a discriminatory idea against a protected class of people, or seeks confirmation of a stereotype
- Makes disparaging attacks/insults against a specific person or group of people
- Based on an outlandish premise about a group of people
- Disparages against a characteristic that is not fixable and not measurable
- Isn’t grounded in reality
- Based on false information, or contains absurd assumptions
- Uses sexual content (incest, bestiality, pedophilia) for shock value, and not to seek genuine answers
Train and Test Data
The training data includes the question that was asked, and whether it was identified as insincere (target = 1). The ground-truth labels contain some amount of noise.
train.csv
| ID | Question Text | Target |
|---|---|---|
| 0 | How did Quebec nationalists see their province… | 0 |
| 1 | Do you have an adopted dog, how would you enco… | 0 |
| 2 | Why does velocity affect time? Does velocity … | 0 |
| 3 | How did Otto von Guericke used the Magdeburg … | 0 |
| 4 | Can I convert montra helicon D to a mountain… | 0 |
test.csv
| ID | Question Text |
|---|---|
| 0 | Why do so many women become so rude and arroga… |
| 1 | When should I apply for RV college of engineer… |
| 2 | What is it really like to be a nurse practiti … |
| 3 | Who are entrepreneurs? |
| 4 | Is education really making good people nowaday… |
Embeddings Provided
- Google News Vectors Negative - 300D
- GloVe 840B - 300D
- Paragram - 300D
- Wiki News - 300D 1M
Cleaning Data
The following preprocessing steps are performed -
- Converting all characters to lower case ones.
- Replacing numbers by #s
- Removing and cleaning punctuations (inserting a single space across punctuations)
- Correcting common mis-spelled words
def clean_text(x):
x = str(x)
for punct in puncts:
if punct in x:
x = x.replace(punct, f' {punct} ')
return x
def clean_numbers(x):
x = re.sub('[0-9]{5,}', '#####', x)
x = re.sub('[0-9]{4}', '####', x)
x = re.sub('[0-9]{3}', '###', x)
x = re.sub('[0-9]{2}', '##', x)
return x
def _get_mispell(mispell_dict):
mispell_re = re.compile('(%s)' % '|'.join(mispell_dict.keys()))
return mispell_dict, mispell_re
mispellings, mispellings_re = _get_mispell(mispell_dict)
def replace_typical_misspell(text):
def replace(match):
return mispellings[match.group(0)]
return mispellings_re.sub(replace, text)
Preprocessing the data increases the percentage of vocabulary that is present in the embeddings. The percentage coverage for GloVe, Paragram and Wiki News embeddings increases to around 99.5%.
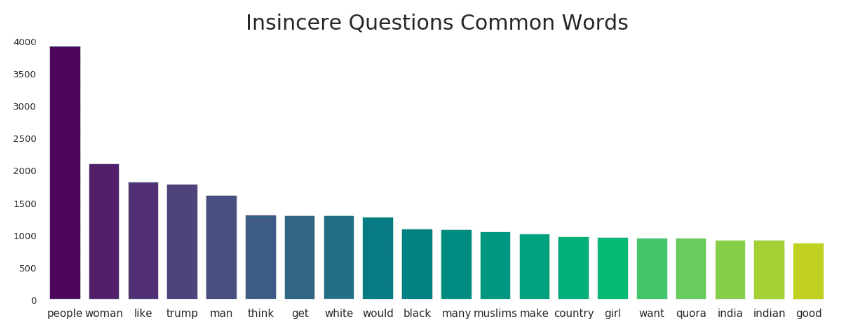
Common Words found in Insincere Questions
Models
Since this was a kernel-only competition, the following limits were imposed on code -
- GPU Kernel <= 2 hours run-time
- No external data
- No custom packages
Thus, we need to use simpler models with small run-times. So, our final solution consisted of a simple weighted linear average of following five deep learning models -
- LSTM + GRU (each with 128 hidden units) + Attention, with averaged GloVe and Paragram embeddings
- LSTM + GRU (128) + Attention + Capsule, with averaged GloVe and Paragram embeddings + Gaussian Noise
- LSTM + GRU (60), with Wiki News embeddings
- LSTM + GRU (80), with Wiki News embeddings with different proprocessing
- LSTM + GRU (80), with averaged GloVe and Paragram embeddings + Gaussian Noise
Each model is train for around 6 epochs on the training set with Adam optimizer and cyclic learning rates. The solution has a runtime of 6352 seconds as compared to total runtime of 7200 seconds.
Results
- The overall model got a F1 score of 0.70658 on private LB.
- Appropriate preprocessing increases the percentage of vocabulary that is present in the embeddings. This translates to a corresponding increase in performance of individual models.
- Averaging GloVe and Paragram embeddings provides a considerable improvement in score as compared to individual ones. Also, the use of averaged embedddings rather then concatenated ones reduces the training time.
- Models with Wiki News embeddings achieved scores comparable to other models.
- Adding Gaussian Noise after embeddings reduces the overdependence of LSTM on specific irrelevant words.
- Creating diverse models improves the overall F1 score.
- Using cylic learning rate scheduler while training allows the model to converge faster. This reduces the training time (by 2-3 epochs).
- The effects of random initialization were dominant in this competition. So, fixing this using a particular seed was important.
- PyTorch is faster than Keras.
- It is important to find a good validation set which correlates with the test set.
Thank You!
Important Links
GitHub Repository
Quora Insincere Questions Classification
How to preprocess when using embeddings
Summary of our solution by Soham
Cyclic Learning Rates for training Neural Networks