Predictive Threat Intelligence

Bachelor Thesis at CoE-CNDS Lab, VJTI under Prof. Dr. Faruk Kazi.
Today, threat intelligence has become one of the emerging cynosures of information security. It’s main functions include identifying the potential threats and predicting the nature of an attacker. Big data analytics solutions, backed by machine learning and artificial intelligence, can help tackle such problems of cybersecurity breach and hacking. By employing the power of big data and machine learning, we can significantly improve cyber threat detection mechanisms. Most recent work has focused on the detection of concrete network attacks using Intrusion Detection Systems (IDS) to raise an alert which subsequently requires human attention. However, we think inspecting the behavioural aspect of an attacker is more intuitive in order to take necessary security measures. So, in this work, we exploit machine learning algorithms for modelling attacker behaviour in order to better foresee his/her future actions. The results of these models are used to analyze different attack propagation and interaction patterns present in the system. These patterns can be used for a better understanding of the existing or evolving attacks and may also aid security experts to comprehend the mindset of an attacker. Additionally, we incorporate these machine learning algorithms into a big data system utilizing Kafka Streams. The code for this post can be found in this GitHub repository.
Data Collection
For training and test the machine learning algorithms, we use a dataset consisting of over a million simulated attacks on a Cowrie honeypot system. Cowrie is a medium interaction SSH and Telnet honeypot designed to log brute force attacks and the shell interaction performed by the attacker. We setup Cowrie Honeypot at CoE-CNDS, VJTI. Cowrie honeypot logs user activity in JSON files with distinct focus on terminal inputs and messages. The default JSON logging format employed is shown below-
{
"eventid": "cowrie.client.version",
"macCS": ["hmac-sha1", "hmac-sha1-96", "hmac-md5", "hmac-md5-96",
"hmac-ripemd160", "hmac-ripemd160@openssh.com"],
"timestamp": "2017-07-03T18:30:08.235671Z",
"session": "577076dfb79e",
"kexAlgs": ["diffie-hellman-group14-sha1",
"diffie-hellman-group-exchange-sha1",
"diffie-hellman-group1-sha1"],
"keyAlgs": ["ssh-rsa", "ssh-dss"],
"message": "Remote SSH version: SSH-2.0-PUTTY",
"system": "HoneyPotSSHTransport,523,116.31.116.16",
"isError": 0,
"src_ip": "116.31.116.16",
"version": "SSH-2.0-PUTTY",
“dst_ip”: “10.10.0.13”,
"compCS": ["none"],
"sensor": "DC-NIC-Mumbai",
"encCS": ["aes128-ctr", "aes192-ctr", "aes256-ctr", "aes256-cbc",
"rijndael-cbc@lysator.liu.se", "aes192-cbc", "aes128-cbc",
"blowfish-cbc", "arcfour128","arcfour",
"cast128-cbc","3des-cbc"]
}
Data Analysis and Preprocessing
A detailed analysis of the collected Cowrie honeypot logs can be found here.
This section provides some analysis of the field ‘Event ID’, which will be used for subsequent modelling purposes. Event ID is a tag given to the activity of the attacker.
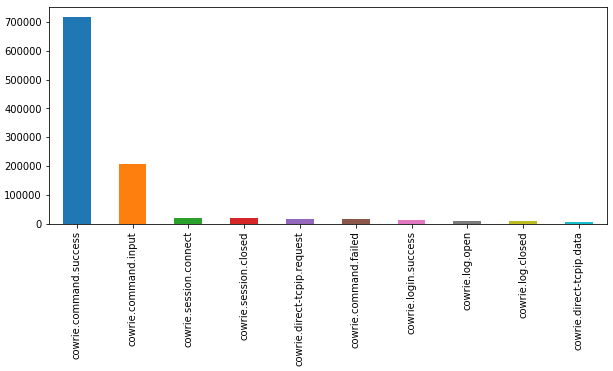
Number of occurrences of particular ‘Event ID’
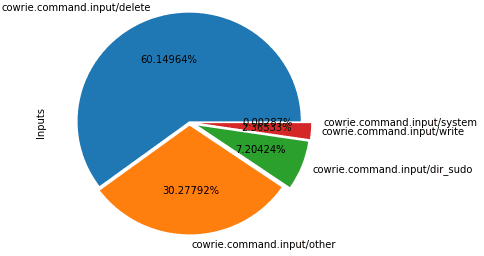
Distribution of Input Events
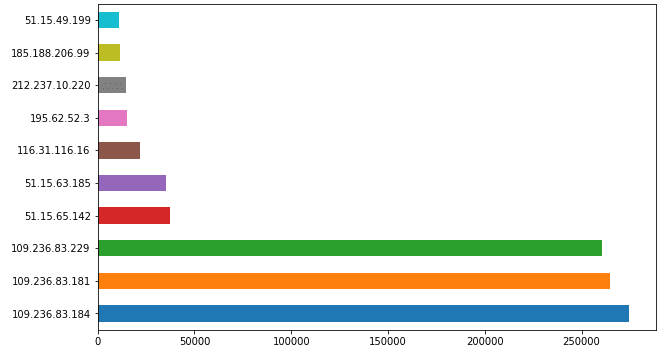
Most Common IPs involved in Attacks
The logged cowrie activity has 14 states each representing a particular event ID. The input command was then divided into 5 commands specifically write, system, sudo, delete and other with prominently emphases the malicious behaviour of attacker. The total 19 states are given below along with their corresponding IDs -
0: ‘cowrie.client.size’, 1: ‘cowrie.client.version’, 2: ‘cowrie.command.failed’, 3: ‘cowrie.command.input/delete’, 4: ‘cowrie.command.input/dir_sudo’, 5: ‘cowrie.command.input/other’, 6: ‘cowrie.command.input/system’, 7: ‘cowrie.command.input/write’, 8: ‘cowrie.command.success’, 9: ‘cowrie.direct-tcpip.data’, 10: ‘cowrie.direct-tcpip.request’, 11: ‘cowrie.log.closed’, 12: ‘cowrie.log.open’, 13: ‘cowrie.login.failed’, 14: ‘cowrie.login.success’, 15: ‘cowrie.session.closed’, 16: ‘cowrie.session.connect’, 17: ‘cowrie.session.file_download’ and 18: ‘cowrie.session.input’
The data is grouped by session ID for constructing each sequence where each session ID corresponds to the sequence of actions taken by hacker.
Machine Learning Models
We use three different models for modelling the attack sequences occurring on Cowrie honeypot and predict the future steps which may be taken by the attacker which might occur on the honeypot system.
- Markov Chain
- Hidden Markov Model
- LSTM
Markov Chain
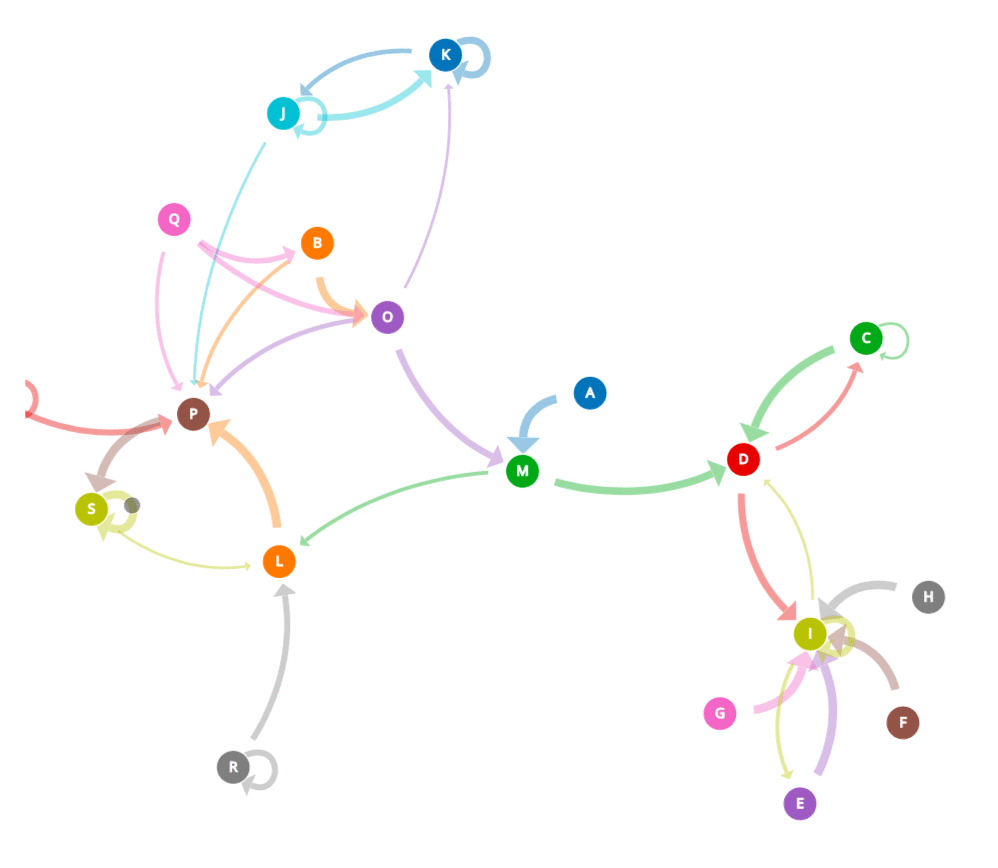
A Markov chain is a stochastic process that sequentially moves from one state to another in the state space. In the context of analyzing honeypot attack sequences, we train a probabilistic model which efficiently models the intruder attack sequences on Cowrie honeypot. A first-order Markov chain having states X = { xi : i = 0, 1, …, 18 } is being used for the purpose, where each state represents the ID of the event logged by the honeypot in response to the action taken by the attacker. According to a first order Markov chain, the probability of a state X at instant t is dependent only on the state at instant t-1. Thus, we need to find the probabilities P(Xi | Xj) that if Xj is the current step, then the next step would be Xi. Training a Markov model involves calculating these transition probabilities using the number of transitions from state i to state j in the training sequences. The resulting Markov chain can be used to predict the next step which the attacker might take depending on the current step of the attacker.
The transition matrix can be used to generate a state propagation graph with 19 nodes and 69 edges, as shown below.
Hidden Markov Model
Hidden Markov Model (HMM) is a statistical Markov model with the unobserved states. In HMM the states are not visible, but the output depends on states that are visible. HMM is completely defined by:
ɸ = (A, B, π)
where,
- Transition Probability Matrix A = { aij }, where aij is the probability of taking a transition from state i to state j.
- Output Probability Distribution/Emission Matrix B = { bi(k) }, where bi(k) is the probability of emitting symbol ok when in state i.
- Initial State Distribution π.
In our context, the idea is to find values for ɸ = (A, B, π) such that the probability of the training observations is maximised. We perturb the parameters until they can no longer be improved i.e., the model is trained using the conventional Baum-Welch algorithm (which is a type of EM algorithm).
The convergence (logarithmic probabilities) of the Hidden Markov Model being trained using EM algorithm is shown below -
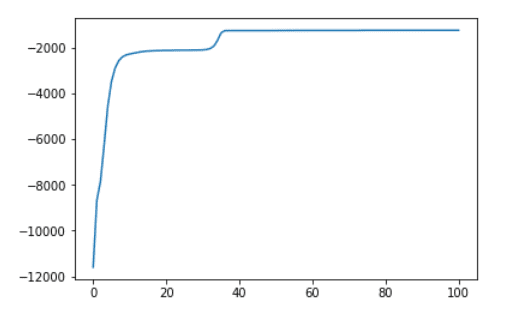
The results of Hidden Markov Model are similar to that obtained from Markov Chain. But testing on real time logs of attacker actions for 1 month (which we did not use for training) showed a prediction accuracy of 77% as compared to Markov chain which had 72% accuracy.
Generative LSTM-based Model
Long Short-Term Memory (LSTM) is a modified version of recurrent neural network. A LSTM cell is composed of an input gate, an output gate and a forget gate. LSTM solves the vanishing gradient problem commonly faced in RNNs which allows it to remember long sequences. Thus, a generative model based on LSTM is able to capture such long-term dependencies in attack sequencs and provides a much better prediction accuracy due to fact that some proficient hackers tend to lurk in the system doing benign actions for a long time. However, this improvement comes at the cost of increased training and prediction time. In addition, we modify the output layer of LSTM model so as allow it to predict next 10 future states.
Before training the LSTM-based model, we need to process data as follows:
- Pad each attack sequence to a fixed length of hundred and ten future actions are considered as output. A sliding window approach was used for maximum utilization of data.
- Input sequences of action less than hundred and output sequences of action less than ten are padded with 0s.
- Normalize inputs and outputs.
The training task is framed as regression with mean squared error (MSE) as loss function. The model is trained for 1000 epochs with a batch size of 256.
Overall System Architecture
Kafka streams form the backbone of the overall system. The use of Kafka allows the system to store, stream and process large amounts of data logs and generate predictions using the machine learning algorithms at scale.
Kafka
Apache Kafka is a publish/subscribe messaging system, commonly described as a “distributed commit log . The data within Kafka is stored durably, in order, and can be read deterministically. In addition, the data can be distributed within the system to provide additional protections against failures, as well as significant opportunities for scaling performance.
Kafka is generally used for two broad classes of applications -
- Building real-time streaming data pipelines that reliably get data between systems or applications.
- Building real-time streaming applications that transform or react to the streams of data.
Kafka is run as a cluster on one or more servers that can span multiple datacenters. The Kafka cluster stores streams of records in categories called topics. Each record consists of a key, a value, and a timestamp.
Kafka has three major components -
- Producer - Allows an application to publish a stream of records to one or more Kafka topics.
- Consumer - Allows an application to subscribe to one or more topics and process the stream of records produced to them.
- Streams - Allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
System Dataflow
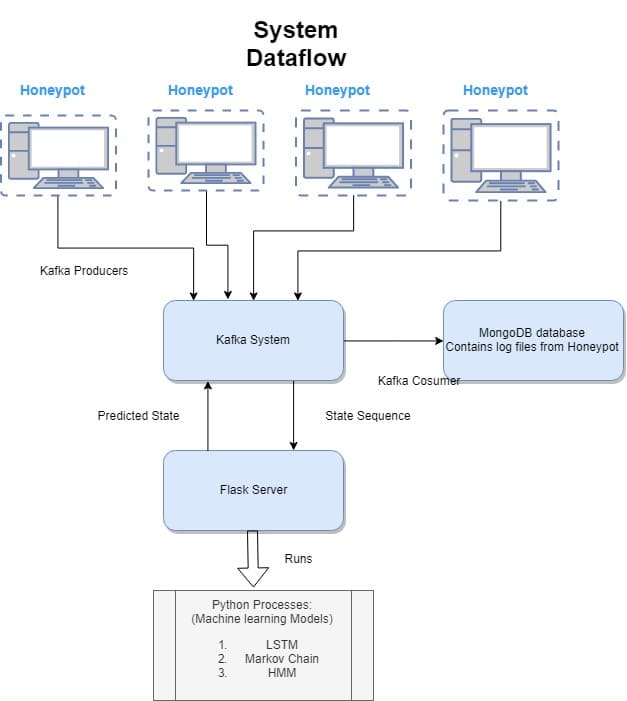
Producer
Each honeypot device has its own producer module. The producer is responsible for publishing the honeypot logs to the brokers. Each producer node subscribes to a cluster of Kafka brokers which automatically distributes the load among themselves. The producer constantly monitors the log produced by honeypot device, converts it to JSON format acceptable to the streamer and publishes it to an input topic. The JSON file consists of attack log details as well as the input offset of the attacker. To maintain the order of the input data, we assign the unique session id of each attacker as the key to the input topic.
Streamer
Kafka Streamer is responsible for real-time prediction of the future attack sequence. It performs a set of map and reduce operations to aggregate and compute the results. The streamer is subscribed to the input topic which is periodically updated by the kafka producer. Each kafka streamer has a flask server which is responsible for computing the predicting via various machine learning algorithms. The server computes the prediction and sends the predicted output back to the streamer. The prediction is stored in JSON format. This map phase produces data in the form of a KStream. This KStream data is flushed back to the kafka broker via an output topic.
Consumer
Each honeypot device has its own consumer module. The consumer module is responsible for publishing the honeypot log data to the MongoDB for the storage. Each consumer node subscribes to a cluster of Kafka brokers which automatically distributes the load among themselves. The consumer constantly monitors the predictions made by Machine learning models, converts it to JSON format acceptable to the MongoDB and publishes it to a corresponding topic. The JSON file consists of predicted states as well as the probability of the attacker sequence.
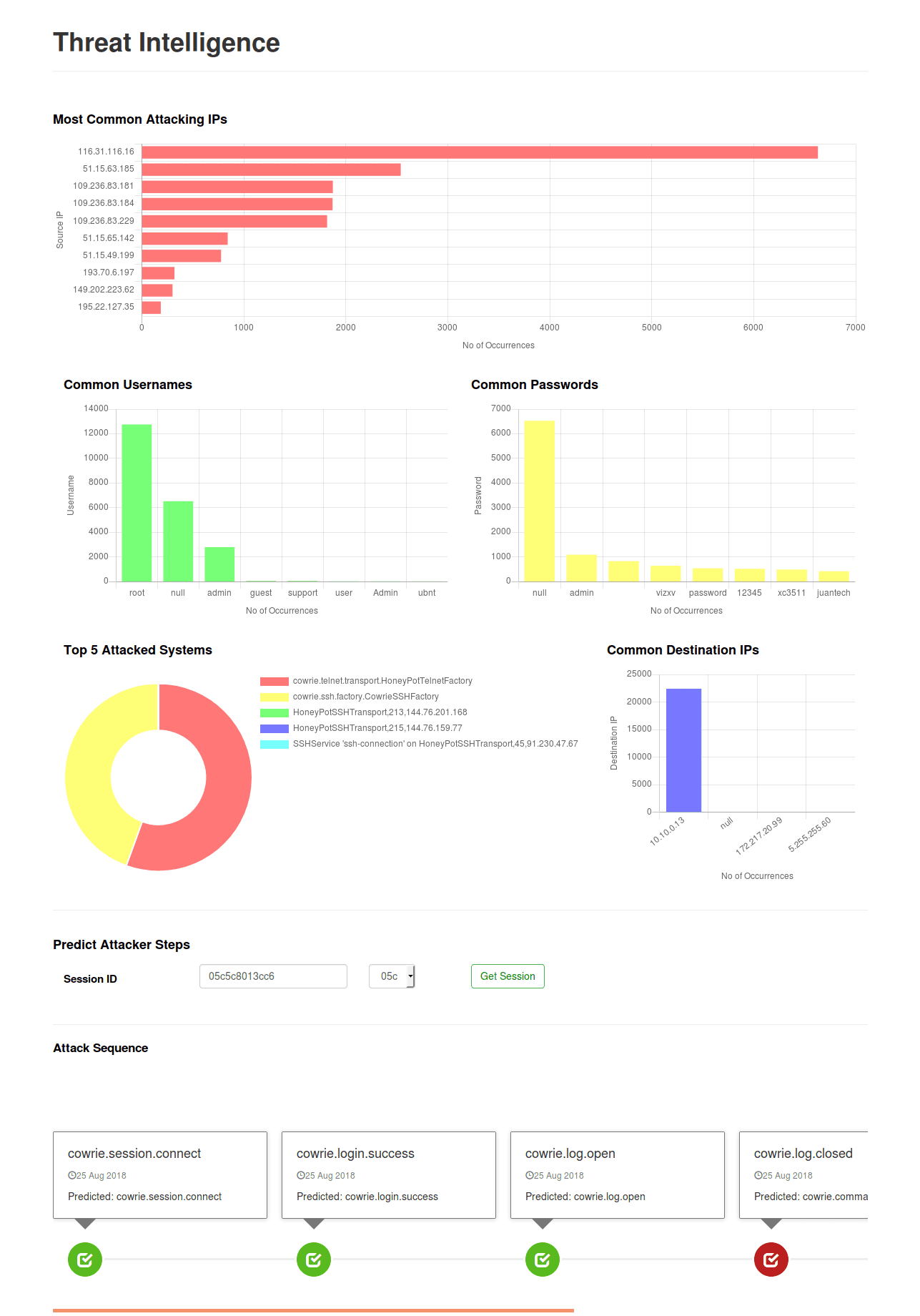
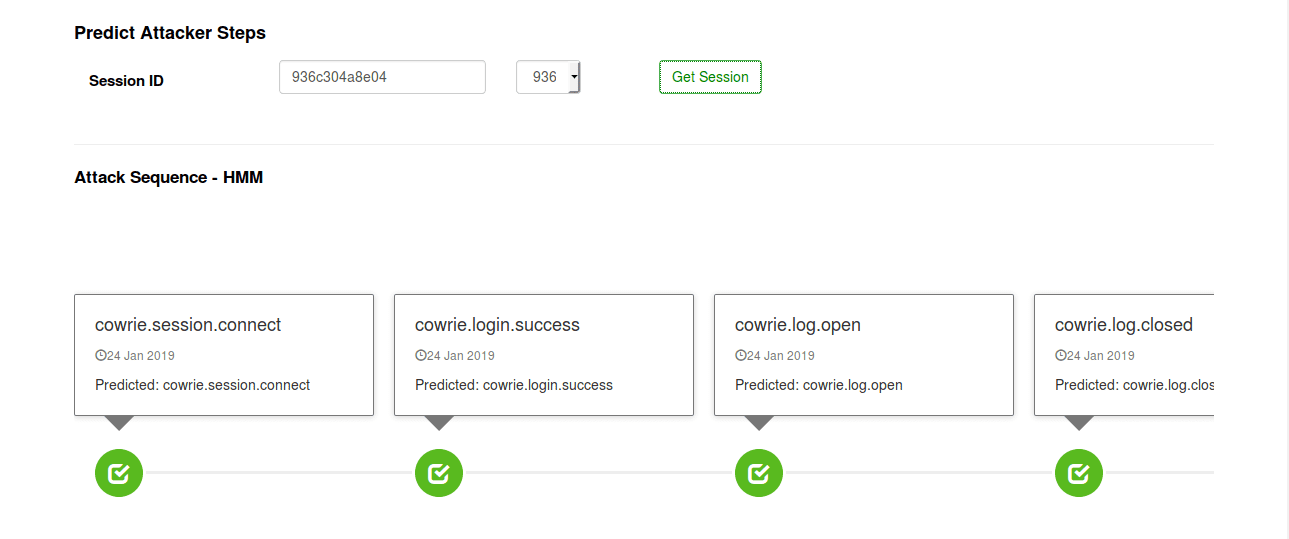
Dashboard
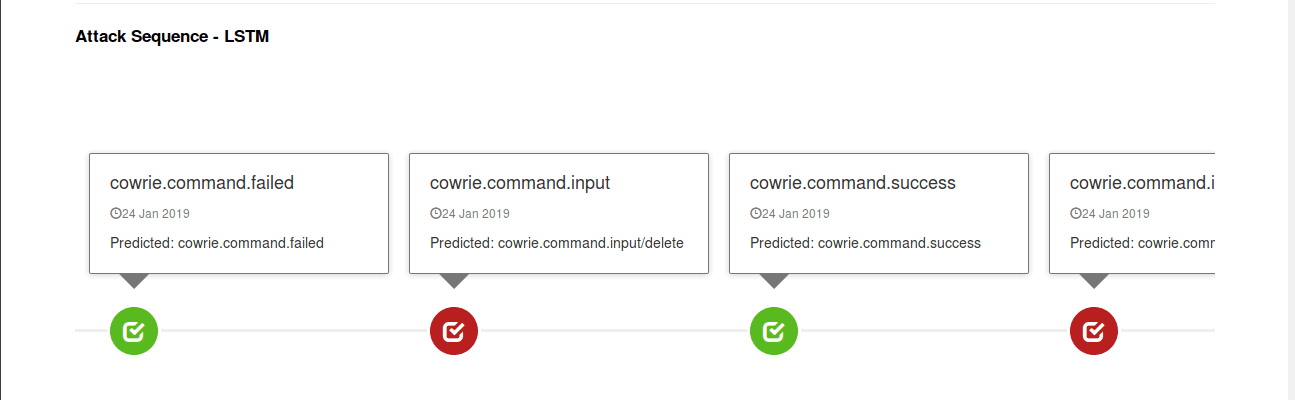
We built a dashboard using Angular and NodeJS. Some screenshots of the dashboard are shown below -
Deployment on DNIF
We also deployed the machine learning algorithms as a look-up plugin consisting of an efficient implementation of our models on DNIF (a next generation SIEM platform). The project also received appreciation from the officials of Cyber Peace Foundation and Mr. Alex Dunbar-Brooks (International Cyber Policy Economist) during their visit at CoE-CNDS Lab, VJTI. This project was also applauded by Mr. Prateek Thube (IPS Officer) during his visit.
Thank You!
Important Links
GitHub Repository
Temporal and Stochastic Modelling of Attacker Behaviour
GitHub - Cowrie Honeypot
Data Analysis of Cowrie Honeypot Logs
Markov Chain and HMMs - Stanford
Apache Kafka
MongoDB