Deepfakes
Work done at CoE-CNDS Lab, VJTI under Prof. Dr. Faruk Kazi.
Deepfake is a technique for human image synthesis based on artificial intelligence. It is used to combine and superimpose existing images and videos onto source images or videos using a machine learning technique called a “generative adversarial network” (GAN). In other words, deepfakes are fake videos or audio recordings that look and sound just like the real thing.
Swapping Faces and Tampering Speech

Threats posed by Deepfakes
Deepfakes have a potential to spread false, misleading information and create malicious hoaxes. So far, deepfakes have been limited to amateur hobbyists putting celebrities’ faces on porn stars’ bodies and making politicians say funny things. However, it would be just as easy to create a deepfake of an emergency alert warning an attack was imminent, or disrupt a close election by dropping a fake video or audio recording of one of the candidates days before voting starts.
So, we at CoE-CNDS, VJTI are working to create a robust solution for detecting fake videos. In order to detect deepfakes, we are trying exploit some of the discrepancies introduced by autoencoder based GANs while generating fakes. So far, we have built a GAN-based architecture which can swap faces in videos. We have created a fake video which brings Jack Ma in Bollywood by replacing Aamir Khan in a 3 Idiots movie scene. This is an attempt, on a lighter side, to show potential threat of AI DeepFakes to launch a campaign of distorted information and thereby mislead society.
How are Deepfakes created?
The main backbone of the network used in creating the above Deepfake is an autoencoder-based GAN network.
Generative Adverserial Networks
Generative adverserial networks (GANs) are deep neural net architectures comprised of two nets - generator and discriminator, competing with each other. The generator network learns to generates new data instances, say images, while the discriminator, evaluates them for authenticity; i.e. it classifies these images as real or fake. So, the generator and discriminator are in a double feedback loop and push each other to get better in its task.
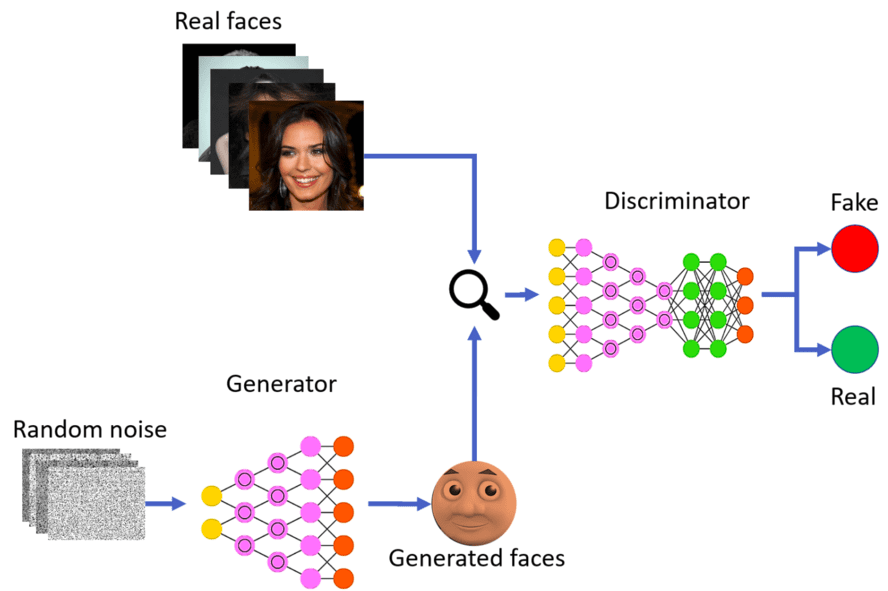
GANs have a huge potential because they can learn to mimic any distribution of data. They can be taught to create worlds eerily similar to our own in any domain: images, music, speech, prose.
Overall Architecture
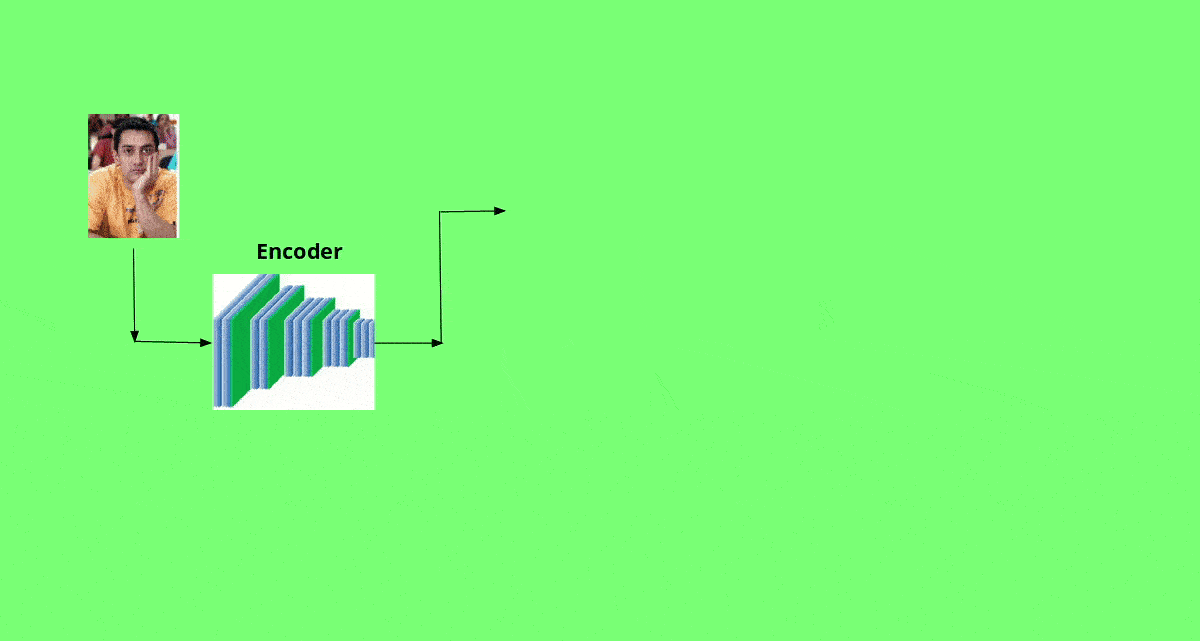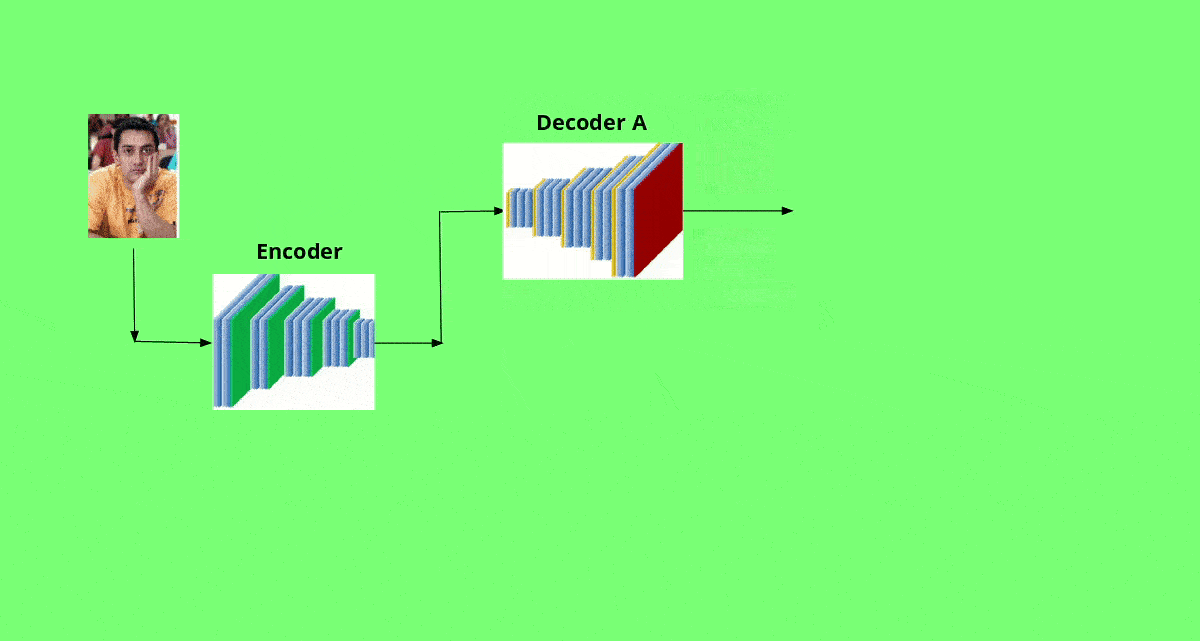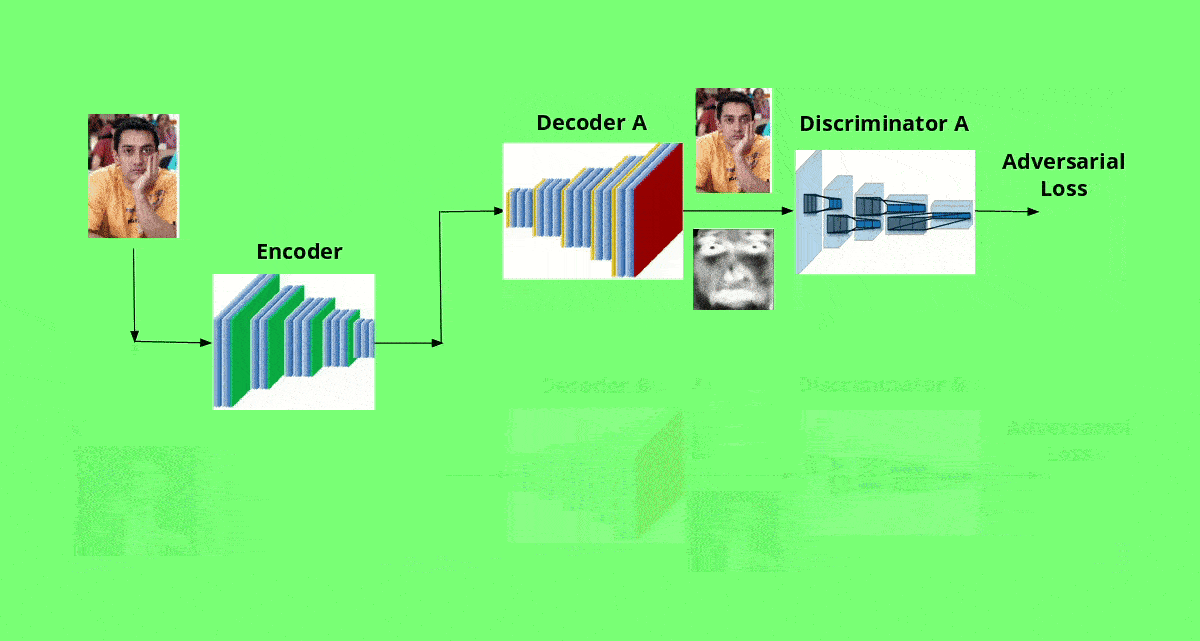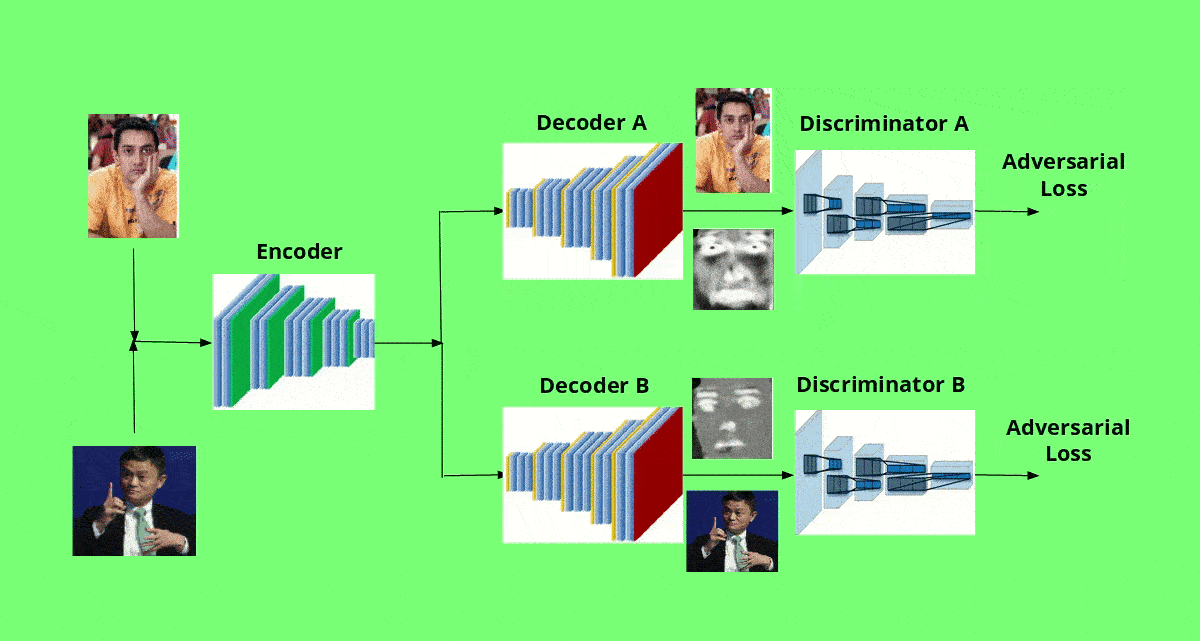
The overall architecture is very simple. Suppose we want to swap face of person A with person B in a video.
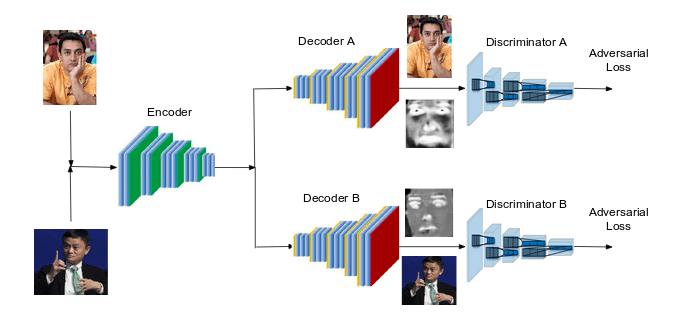
First, we train a CNN-based encoder network on the hundreds of images of A and B. The encoder learns to encode the features of each images such as facial expressions, face shape, skin tone, lighting and other orientation information. Thus, the encoder learns to produce an efficient representation of the image. The output of the encoder is presented to a CNN-based decoder network. The decoder network learns to reconstruct the images. In addition to generating images, the decoders generate masks as well. These masks help in producing more realistic images after face swapping.
Since we have two different distributions corresponding to A and B, we use two separate decoders which learn to reconstruct faces A and B respectively. The encoder needs to extract the most important features to recreate the original input for the decoders to work as desired. Such a encoder-decoder commbination is commonly called as autoencoder, and forms the generator net of our GAN. Thus, we have two GANs - GAN A (consisting of encoder and decoder A) and GAN B (consisting of the same encoder and decoder B).
In addition, we use two separate discriminators A and B, where each one learns to differentiate between real and fake images better. When we feed generated images into the respective discriminator, the adverserial loss pushes the generator to generate more realistic images. This eventually becomes a race until the generated images are not distinguishable from the real ones.
It takes 15 hours to train the network on Nvidia Tesla V100 GPU for around 50,000 iterations.
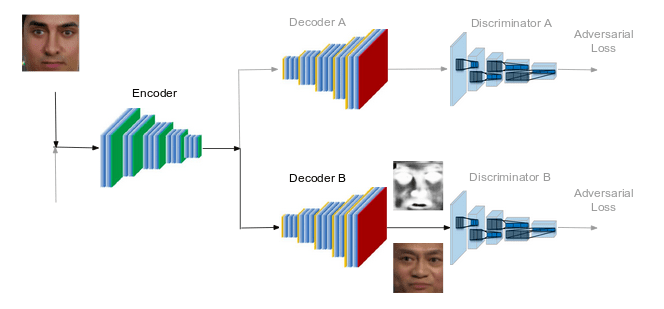
After training, during the swapping phase, if we want to swap the face of person A with face of person B, we pass the image A through the ecoder and use the decoder B to reconstruct the image. Since the decoder B has learnt to generate face B, we are essentially trying to generate face B with features of face A from the original image. In short, we have swapped the face A with face B. For generating videos, we need to repeat this step for each frame in the video.
Some preprocessing and postprocessing techniques can be used to make better fake videos.
Results
Our current research mainly focuses on exploiting features in generative fake videos in order to detect and identify the fake videos better. More insights and results are provided below.

- The network is trained for 50,000 iterations. This takes 15 hours on Nvidia Tesla V100 GPU.
- We use custom loss functions to penalize the region around the eyes and the lips for generating realistic-looking facial movements. This also results in better consistency between source & target eye and lip movements.
- Using self-attention in the network produces superior videos with higher output quality.
- When closely inspected, we can see that the generated faces don’t always match the exact positioning of the source face. When the network tries to blend such a generated face into the surroundings, it leaves digital artifacts in the resulting video. This also happens when there are sharp facial expressions in the source video.
- Morover, these situations can make a video look obviously doctored with blurry borders and artificially smooth skin, and can be exploited to identify fake videos.

The code for this with be shortly provided. To be updated.
Thank You!
Important Links
Generative Adverserial Networks
Deepfakes
How and why deepfake videos work — and what is at risk
Synthesizing Obama: Learning Lip Sync from Audio
Self-Attention Generative Adversarial Networks